Скачать с ютуб DocuXplorer: Extracting Text and OCR в хорошем качестве
DocuXplorer: Extracting Text and OCR
9 лет назад
Из-за периодической блокировки нашего сайта РКН сервисами, просим воспользоваться резервным адресом:
Загрузить через dTub.ru Загрузить через ClipSaver.ruСкачать бесплатно DocuXplorer: Extracting Text and OCR в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно DocuXplorer: Extracting Text and OCR или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон DocuXplorer: Extracting Text and OCR в формате MP3:
Роботам не доступно скачивание файлов. Если вы считаете что это ошибочное сообщение - попробуйте зайти на сайт через браузер google chrome или mozilla firefox. Если сообщение не исчезает - напишите о проблеме в обратную связь. Спасибо.
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса savevideohd.ru
DocuXplorer: Extracting Text and OCR
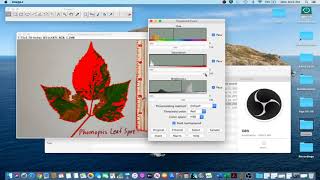
Using DocuXplorer’s text extraction feature, you can easily capture text from a PDF or electronic document for quick and easy keyword searches from within the document. With our new Unicode version, DocuXplorer users can now extract text in English, German, Arabic, Russian, Japanese or even Tagalog! Optical character recognition (OCR) is the electronic conversion of scanned images of typewritten or printed text into machine-encoded text. DocuXplorer’s advanced, built-in OCR functionality allows users to search for text that has been OCR’d in 26 languages.
Comments






![971+ Compxm Final Exam Answers 2025 [Compxm Round 1 to 4 Answers Included]](https://i.ytimg.com/vi/wMx8Gf2uvjo/mqdefault.jpg)