Скачать с ютуб Depth First & Breadth First Graph Search - DFS & BFS Graph Searching Algorithms в хорошем качестве
Depth First & Breadth First Graph Search - DFS & BFS Graph Searching Algorithms
5 лет назад
Скачать бесплатно Depth First & Breadth First Graph Search - DFS & BFS Graph Searching Algorithms в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно Depth First & Breadth First Graph Search - DFS & BFS Graph Searching Algorithms или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон Depth First & Breadth First Graph Search - DFS & BFS Graph Searching Algorithms в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса savevideohd.ru
Depth First & Breadth First Graph Search - DFS & BFS Graph Searching Algorithms
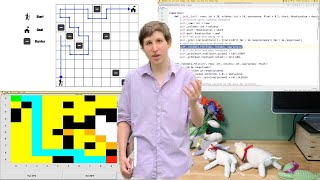
Free 5-Day Mini-Course: https://backtobackswe.com Try Our Full Platform: https://backtobackswe.com/pricing 📹 Intuitive Video Explanations 🏃 Run Code As You Learn 💾 Save Progress ❓New Unseen Questions 🔎 Get All Solutions DFS and BFS are not just graph search algorithms. They are a fundamental method for searching relationships in a certain way and visiting nodes of any sort in a desired order. These relationships may be represented in a graph, or we may be checking the distance one string is in character changes from another string, OR we may be traversing a tree a certain way. These are searching concepts, not just graph concepts. Implementation DFS can be done iteratively using a stack or done recursively because the call stack will serve as the stack to remember points to backtrack to. A stack structure can replace our stack frames from recursion, this is why DFS can be written recursively, due to the Last-In-First-Out (LIFO) of the order nodes are processed. BFS is done iteratively. It uses a queue that has a First-In-First-Out processing order. Use Cases DFS is good for things like backtracking, getting to leaf nodes in a tree, or anything where we want to prioritize going very deep into a path and exhausting possibilities before coming back. BFS is better for things like finding if a path exists between one node to another since it prioritizes width of search over depth (hence "breadth-first") and finding distance or "levels" something is away from something else. The Method 1.) Choose the data structure based on the search. 2.) Add the start node. 3.) Remove the a node from the data structure. 4.) If the node has not been seen 4a.) Mark it as seen in the "seen" set. 4b.) Do work on the node. 5.) For each of the children 5a.) If child has not been seen (not bee processed) 5ai.) Add the child to the data structure. Repeat while the data structure is not empty. Time Complexities If relationships are represented with an adjacency list then: Time: O(V + E) Space: O(V)* Where V is the total number of vertices (or nodes) visited and E is the total numbers of edges traversed. *Although things will vary. We only care about the MAXIMUM amount of nodes in the data structure at one time. If we are doing DFS on balanced tree the space complexity would be O(h) where h is the height of the tree since we would only have a path h nodes long at MAX living on the stack. Same for if we do a level order traversal of a tree. The space will only be the MAXIMUM WIDTH of the tree because we would only keep that many nodes on the queue at MAX at one time. And on and on...just depends, ask your interviewer whether they want worst, average, or best case analysis. "adjacency list" means each node stores its adjacent neighbors in a list ++++++++++++++++++++++++++++++++++++++++++++++++++ HackerRank: / @hackerrankofficial Tuschar Roy: / tusharroy2525 GeeksForGeeks: / @geeksforgeeksvideos Jarvis Johnson: / vsympathyv Success In Tech: / @successintech
Comments