РЎРәР°СҮР°СӮСҢ СҒ СҺСӮСғРұ How to solve Multi-Label Classification Problems in Deep Learning with Tensorflow & Keras? РІ С…РҫСҖРҫСҲРөРј РәР°СҮРөСҒСӮРІРө
How to solve Multi-Label Classification Problems in Deep Learning with Tensorflow & Keras?
3 РіРҫРҙР° РҪазаРҙ
РЎРәР°СҮР°СӮСҢ РұРөСҒРҝлаСӮРҪРҫ How to solve Multi-Label Classification Problems in Deep Learning with Tensorflow & Keras? РІ РәР°СҮРөСҒСӮРІРө 4Рә (2Рә / 1080p)
РЈ РҪР°СҒ РІСӢ РјРҫР¶РөСӮРө РҝРҫСҒРјРҫСӮСҖРөСӮСҢ РұРөСҒРҝлаСӮРҪРҫ How to solve Multi-Label Classification Problems in Deep Learning with Tensorflow & Keras? или СҒРәР°СҮР°СӮСҢ РІ РјР°РәСҒималСҢРҪРҫРј РҙРҫСҒСӮСғРҝРҪРҫРј РәР°СҮРөСҒСӮРІРө, РәРҫСӮРҫСҖРҫРө РұСӢР»Рҫ загСҖСғР¶РөРҪРҫ РҪР° СҺСӮСғРұ. ДлСҸ СҒРәР°СҮРёРІР°РҪРёСҸ РІСӢРұРөСҖРёСӮРө РІР°СҖРёР°РҪСӮ РёР· С„РҫСҖРјСӢ РҪРёР¶Рө:
ЗагСҖСғР·РёСӮСҢ РјСғР·СӢРәСғ / СҖРёРҪРіСӮРҫРҪ How to solve Multi-Label Classification Problems in Deep Learning with Tensorflow & Keras? РІ С„РҫСҖРјР°СӮРө MP3:
Р•СҒли РәРҪРҫРҝРәРё СҒРәР°СҮРёРІР°РҪРёСҸ РҪРө
загСҖСғзилиСҒСҢ
РқРҗР–РңРҳРўР• ЗДЕСЬ или РҫРұРҪРҫРІРёСӮРө СҒСӮСҖР°РҪРёСҶСғ
Р•СҒли РІРҫР·РҪРёРәР°СҺСӮ РҝСҖРҫРұР»РөРјСӢ СҒРҫ СҒРәР°СҮРёРІР°РҪРёРөРј, РҝРҫжалСғР№СҒСӮР° РҪР°РҝРёСҲРёСӮРө РІ РҝРҫРҙРҙРөСҖР¶РәСғ РҝРҫ Р°РҙСҖРөСҒСғ РІРҪРёР·Сғ
СҒСӮСҖР°РҪРёСҶСӢ.
РЎРҝР°СҒРёРұРҫ Р·Р° РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРө СҒРөСҖРІРёСҒР° savevideohd.ru
How to solve Multi-Label Classification Problems in Deep Learning with Tensorflow & Keras?
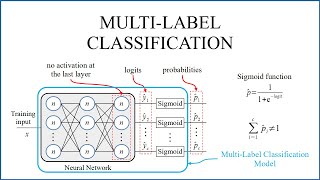
Access all tutorials at https://www.muratkarakaya.net Classification Tutorials: В В В вҖўВ ClassificationВ withВ KerasВ /В TensorflowВ В Keras Tutorials: В В В вҖўВ KerasВ TutorialsВ В tf.data Pipeline: В В В вҖўВ TensorFlowВ DataВ Pipeline:В HowВ toВ Desi...В В Colab: https://colab.research.google.com/dri... This is the fourth part of the "How to solve Classification Problems in Keras?" series. Before starting this tutorial, I strongly suggest you go over Part A: Classification with Keras to learn all related concepts. The link to all the parts of the series is provided in the video description. In this tutorial, we will focus on how to solve Multi-Label Classification Problems in Deep Learning with Tensorflow & Keras. First, we will download a sample Multi-label dataset. In multi-label classification problems, we mostly encode the true labels with multi-hot vectors. We will experiment with combinations of various last layer's activation functions and loss functions of a Keras CNN model and we will observe the effects on the model's performance. During experiments, we will discuss the relationship between Activation & Loss functions, label encodings, and accuracy metrics in detail. We will understand why sometimes we could get surprising results when using different parameter settings other than the generally recommended ones. As a result, we will gain insight into activation and loss functions and their interactions. In the end, we will summarize the experiment results in a cheat table. If you would like to learn more about Deep Learning with practical coding examples, please subscribe to my YouTube Channel or follow my blog on Medium. Do not forget to turn on notifications so that you will be notified when new parts are uploaded. You can access this Colab Notebook using the link given in the video description below. If you are ready, let's get started! PARTS Part A : Classification in Deep Learning Part B: Binary classification Part C: Multi-Class classification Part D: Multi-Label classification References Keras API reference / Losses / Probabilistic losses Keras Activation Functions Tensorflow Data pipeline (tf.data) guide How does tensorflow sparsecategoricalcrossentropy work? Cross-entropy vs sparse-cross-entropy: when to use one over the other Why binary_crossentropy and categorical_crossentropy give different performances for the same problem? Download First let's load the data from Image Data for Multi-Instance Multi-Label Learning Create a Keras CNN model by using Transfer learning Import VGG16 To train fast, let's use Transfer Learning by importing VGG16 Pay attention: The last layer has number_of_classes units. So the output (y_pred) will be a vector with number_of_classes dimension. For the last layer, the activation function can be: None sigmoid softmax When there is no activation function is used in the model's last layer, we need to set from_logits=True in cross-entropy loss functions. Thus, cross-entropy loss functions will apply a sigmoid transformation on predicted label values by themselves: IMPORTANT: We need to use keras.metrics.BinaryAccuracy() for measuring the accuracy since it calculates how often predictions match binary labels. As we are dealing with multi-label classification and true labels are encoded multi-hot, we need to compare pairwise (binary!): each element of prediction with the corresponding element of true labels. However, SparseCategoricalCrossentropy expects true labels as an integer number. Moreover, we can NOT encode multi-labels as an integer since there would be more than one label for a sample. Therefore, the SparseCategoricalCrossentropy loss functions can NOT handle multi-hot vectors! When softmax is applied as the last layer's activation function, is able to only select a single label as the prediction as softmax normalizes all predicted values as a probability distribution. Only one label could get a higher value than 0.5. Thus, softmax can only predict a SINGLE class at most! in a multi-label problem! So softmax will miss other true labels which lead inferior performance compared to sigmoid. Why does Sigmoid produce the best performance when BinaryCrossentropy Loss Function used? When sigmoid is applied as the last layer's activation function, it is able to select multiple labels as the prediction as sigmoid normalize each predicted logit values between 0 and 1 independently. When no activation function (None) is used, each label prediction gets arbitrary numbers from negative infinitive to positive infinitive. BinaryCrossentropy with from_logits parameters is set True automatically applies sigmoid on these logits. Thus, in this case, we have a similar performance compared to the case where we use sigmoid for the last layer's activation function. Does CategoricalCrossentropy loss function generate results?
Comments