Скачать с ютуб Strategies for scaling up data mining algorithms в хорошем качестве
Strategies for scaling up data mining algorithms
8 лет назад
Из-за периодической блокировки нашего сайта РКН сервисами, просим воспользоваться резервным адресом:
Загрузить через dTub.ru Загрузить через ClipSaver.ruСкачать бесплатно Strategies for scaling up data mining algorithms в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно Strategies for scaling up data mining algorithms или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон Strategies for scaling up data mining algorithms в формате MP3:
Роботам не доступно скачивание файлов. Если вы считаете что это ошибочное сообщение - попробуйте зайти на сайт через браузер google chrome или mozilla firefox. Если сообщение не исчезает - напишите о проблеме в обратную связь. Спасибо.
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса savevideohd.ru
Strategies for scaling up data mining algorithms
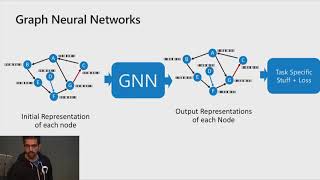
In todayΓÇÖs world, data is generated by and collected from a myriad of disciplines such as mechanical systems, sensor network-based Earth science systems, hardware infrastructures, and information networks. Many of the existing data analysis algorithms do not scale to such large data sets. In this talk, I will present some of our work in speeding up existing data mining algorithms to scale to very large data sets. The first technique will describe how outlier detection can be done in an efficient fashion using an indexing strategy and parallel computing on clusters. This will be followed by a discussion on a general framework for checking model fidelity in very large loosely coupled distributed systems and how the framework can be adapted for system health monitoring.
Comments